
인공지능 전문가들은 스스로 데이터를 학습하여 패턴을 파악하는 비지도기반 학습이 인공지능 기술을 이끌 것이라고 말합니다. 그 과정에서 가장 주목받는 인공지능 기술이 바로 생성적 적대 신경망, GAN(Generative Adversarial Networks)입니다. 따라서 1부에서는 GAN이 속하는 머신러닝의 개념과 분류에 대해 알아보고 제2부에서는 GAN의 원리와 응용사례를 알아보겠습니다.
[인공지능, 머신러닝, 딥러닝의 개념과 관계]
1) 인공지능(Artificial Intelligence)
기계 혹은 시스템에 의해 만들어진 지능으로, 인간이 지닌 지적 능력을 인공적으로 구현한 모든 것을 뜻합니다. 인간의 학습능력, 추론능력, 자연어 이해능력 등을 컴퓨터 프로그램으로 실현한 기술입니다.
2) 머신러닝(Machine Learning)
인공지능 연구 분야 중 하나로, 기계가 코드로 명시하지 않은 동작을 데이터로부터 학습하여 스스로 패턴을 찾아 작업을 실행할 수 있도록 하는 알고리즘이라고 정의됩니다. 즉, 인간의 학습 능력을 컴퓨터에서 실현하는 기술로, 기계가 데이터를 분석하고 ‘스스로’ 학습한 후 그 속에서 패턴 및 규칙성을 찾는 기술입니다.
3) 딥러닝(Depp Learning)
딥러닝은 머신러닝(기계학습)의 일부로, 인간의 뇌 신경망을 모방한 인공신경망의 일종입니다. 머신러닝과 다르게 데이터를 사람이 추출해서 학습시키는 것이 아니라 데이터 자체를 전달하여 학습시키며, 인공신경망 구조를 이용하는 기법입니다.
인공지능, 머신러닝, 딥러닝의 개념 및 관계를 다음 그림을 보면 쉽게 이해할 수 있습니다.

[머신러닝 분류]
머신러닝은 다음 그림처럼 크게 지도기반 학습(Supervised Learning), 비지도기반 학습(Unsupervised Learning), 강화학습(Reinforcement Learning)으로 분류됩니다.
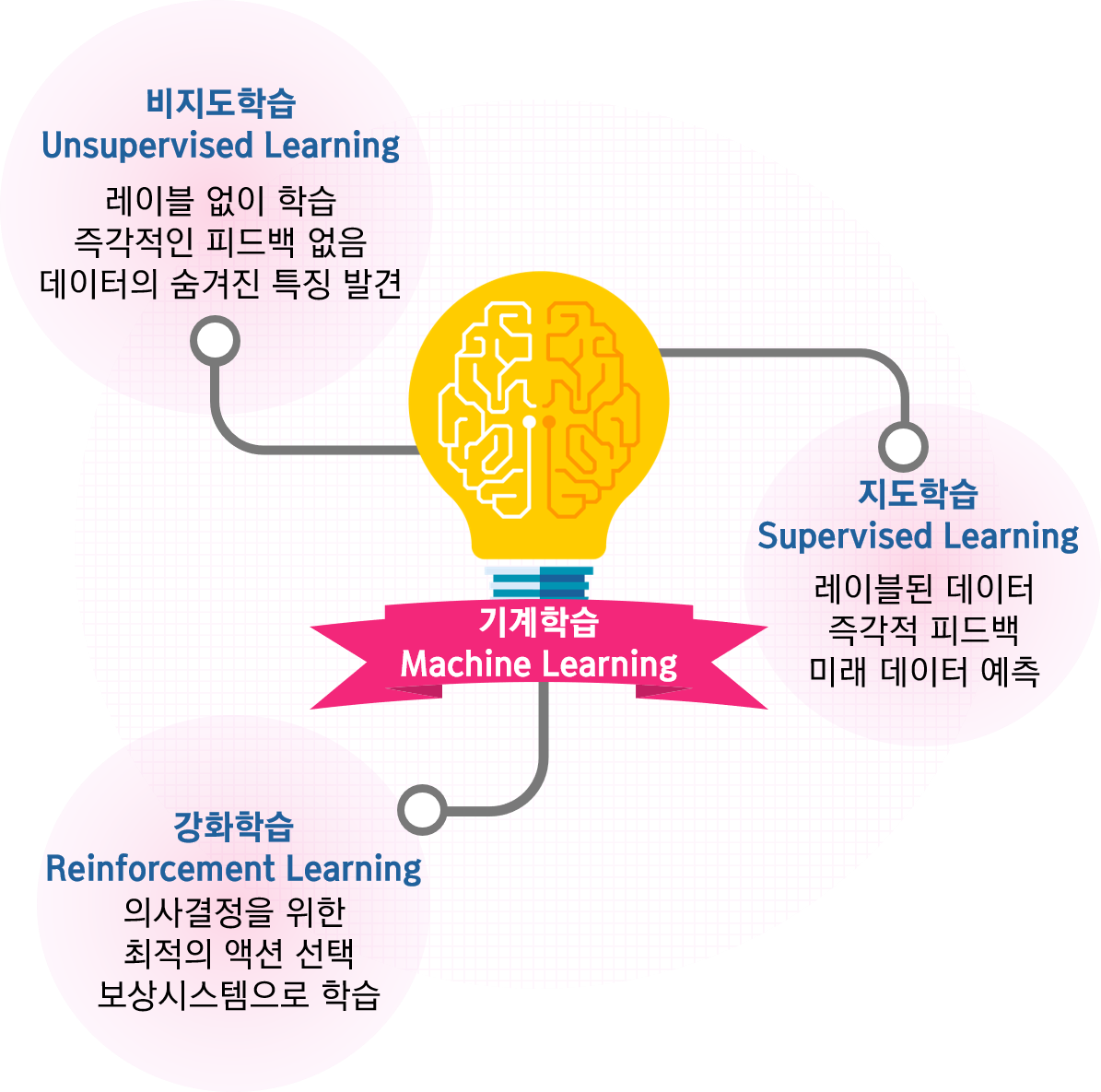
1) 지도학습
지도학습이란 정답이 주어진 상태에서 학습을 하는 알고리즘을 말합니다. 다음 그림처럼 고양이와 토끼의 사진들을 주고 각각의 사진들이 고양이인지 혹은 토끼인지 정답을 알려줍니다. 그 후 어떠한 사진을 주면 이 사진이 고양이인지 혹은 토끼인지 맞추는 것이 바로 지도학습입니다.

지도학습은 예측하는 결과값이 이산값이냐 연속값이냐에 따라 분류(Classification)와 회귀생성(Regression)으로 나뉩니다. 분류란 위의 예시처럼 고양이와 토끼를 구별해 내듯이 어떠한 데이터를 적절한 몇가지의 클래스로 분류하는 것입니다. 위의 예시처럼 토끼, 고양이의 두 개의 클래스로 분류하는 것이 이진 분류(Binary Classification), 여러 개의 클래스로 분류하는 것이 다중 분류(Multiclass Classification)라고 합니다.
회귀생성이란 데이터의 특징을 기반으로 연속적인 값을 예측하는 것입니다. 예를 들어 집의 면적, 위치, 주차장의 유무 등의 데이터로 3년 후 집의 가격을 예측하는 것이 회귀생성의 방법을 사용하는 것입니다. 또한 사람들의 몸무게, 성별, 나이와 같은 데이터로 키를 예측하는 것도 여기에 해당합니다. 최근 딥러닝을 이용한 음성기술 TTS(Text To Speech)에 새로운 이미지 생성이나 목소리를 합성하는데 회귀생성이 쓰인다고 합니다.
2) 비지도학습
비지도 학습의 핵심은 '스스로'라고 말할 수 있습니다. 비지도학습이란 정답이 주어지지 않은 상태에서 데이터의 특성을 학습하여 스스로 패턴을 파악하는 알고리즘을 말합니다. 사람들이 정답을 하나하나 입력하는 수고를 덜어주기 때문에 최근에 집중적으로 연구되는 분야입니다. 가장 오랜 시간 동아 연구되어온 것이 군집화(Clustering)입니다. 다음 그림을 참고하면 이해가 쉽습니다. 고양이와 토끼의 사진을 보고 사람들은 두 개의 긴 귀를 가진 동물과 긴꼬리를 가진 동물로 구분할 수 있습니다. 기계도 이처럼 데이터의 특성을 파악해서 정답을 알려주지 않아도 비슷한 사진으로 분류하는 것을 군집화라고 합니다.

지금까지 본 지도기반학습과 비지도기반학습의 목표는 데이터를 기반으로 미래를 예측하는 것이라고 할 수 있습니다! 하지만 이 두가지 학습법에는 큰 차이가 존재합니다. 지도학습은 정답이 주어진 혹은 정답이 있는 데이터만 사용할 수 있어서 실생활에서 응용하기 복잡하며 데이터 자체에 한계가 있습니다. 하지만 비지도학습은 스스로 데이터를 학습하여 패턴을 파악하기 때문에 더 효율적이고 응용분야도 넓게 나타납니다. 따라서 전문가들은 비지도학습을 미래의 인공지능 기술을 이끄는 알고리즘이 될 것이라고 예측합니다. 그 중 가장 주목받는 기술, 생성적 적대 신경망(GAN)에 대해서는 2부에서 자세히 알려드리도록 하겠습니다.
3) 강화학습
여러분 모두 알파고에 대해서 들어본 적이 있을 것입니다. 구글 딥마인드(DeppMind)에서 만든 인공지능 ‘알파고’와 바둑 세계 챔피언 이세돌의 대국은 전 세계적으로 관심을 받았습니다. 인간과 인공지능의 대결이었죠. 사람들은 당시 이세돌이 승리할 것으로 예상했습니다. 하지만 알파고가 4:1로 이세돌을 이겼습니다. 바둑만은 컴퓨터에게 지지 않을 것이라고 예상했지만 그 예상이 무너지고 컴퓨터가 승리를 가져갔습니다. 그 이후에도 여러 대국이 있었지만 아무도 알파고를 이기지 못했다고 합니다. 현재 알파고는 은퇴를 했고 결국 이세돌이 알파고에게 1승을 한 유일한 인간으로 남게되었습니다. 알파고의 핵심기능이 바로 강화학습이었습니다.
위키피디아에서는 강화학습을 다음과 같이 정의합니다. 강화학습은 기계학습의 한 영역으로 행동심리학에서 영감을 받았다. 어떤 환경(Environment)안에서 정의도니 에이전트(Agent)가 현재의 상태(State)를 인식하여, 선택 가능한 행동(Action) 중 보상(Reward)을 최대화 하는 행동 혹은 행동 순서를 선택하는 방법이다.

강화학습은 딥러닝의 등장 이후 더 주목받기 시작했습니다. 그 전에는 고전적인 강화학습 알고리즘으로 실생활에 적용할 만큼 좋은 결과를 내지 못했기 때문입니다. 하지만 딥러닝의 신경망을 강화학습에 적용하면서 자율주행차나 바둑과 같은 복잡하고 어려운 문제에 적용가능하게 되었습니다. 지금까지 강화학습은 게임에 적용되었고 실생활에서 가치를 창출한 사례는 별로 없습니다. 현재 자율주행차나 로봇에서 실험하는 단계이고 금융분야까지 적용하도록 발전이 이루어지고 있습니다. 이제는 강화학습의 적용 분야에 관한 연구가 필요한 상황이고 자연어 처리의 영역까지 확대되고 있기에 주목할 만한 기술이라고 볼 수 있습니다.
지금까지 인공지능, 머신러닝, 딥러닝의 개념과 머신러닝의 종류에 대해 살펴보았습니다. 다음에는 머신러닝의 비지도학습을 이용한 새로운 기술 GAN의 개념과 응용사례를 알려드리겠습니다.
